
Avante! Há uma grande quantidade de frameworks corporativos como ITIL, Cobit, 6Sigma, Lean e por aí vai. Todos apresentam estratégias interessantes para os negócios, seja do ponto de vista da qualidade, da operação, estratégia ou afins. Além disso, vários apresentam métricas para o melhor acompanhamento do que se pretente. O post DORA Metrics vai apresentar um framework específico para acomapanhamento das entregas de negócio feitas pelo time de desenvolvimento agregando, estratégia, operação e qualidade em apenas 4 indicadores: talvez por isso eu tenha me atraido tanto por ele.
DORA Metrics significa DevOps Research and Assessment Metrics, sendo ela a mais abrangente e antiga pesquisa do tema. Então, a ideia era compreender o que gera efetivamente entregas de valor para o negócio a partir da TI e de que modo. A pesquisa se utiliza dados desde 2014 para chegar a tal conclusão.
Aqui no blog temos vários artigos sobre desenvolvimento, gestão, dados, infraestrutura/operações, kubernetes, DDD e afins. Fique a vontade para explorá-los aqui.
Sumário
O Framework DORA Metrics
Assim, o Framework DORA Metrics ou DevOps Research and Assessment foi uma iniciativa concebida por Nicole Forsgren, Jez Humble e Gene Kim, grandes especialistas em DevOps. Então, eles têm a crença de que uma área de TI que opera bem com práticas ágeis consegue entregar valor e se tornar diferencial competitivo da companhia. Desse modo, 4 métricas foram elaboradas garantindo que elas interajam diretamente, impedindo que seja possível apenas melhorar uma métrica sem se preocupar com o todo.
Portanto as métricas foram elaboradas de forma a garantir uma visão holística de TI, superando os indicadores tradicionais. Assim, entenda que os indicadores são feitos para garantir que a estratégia, tática e operação estejam alinhados, do contrário não funcionaria.
Anualmente o google lança um documento denominado State of DevOps com informações relevantes sobre o tema. A versão de 2022 do documento tem quase 80 páginas onde fala sobre cadeia de suprimentos, nuvem, SRE e Devops, e outros temas com dados, análises e conclusões.
Equilibrio entre as metricas
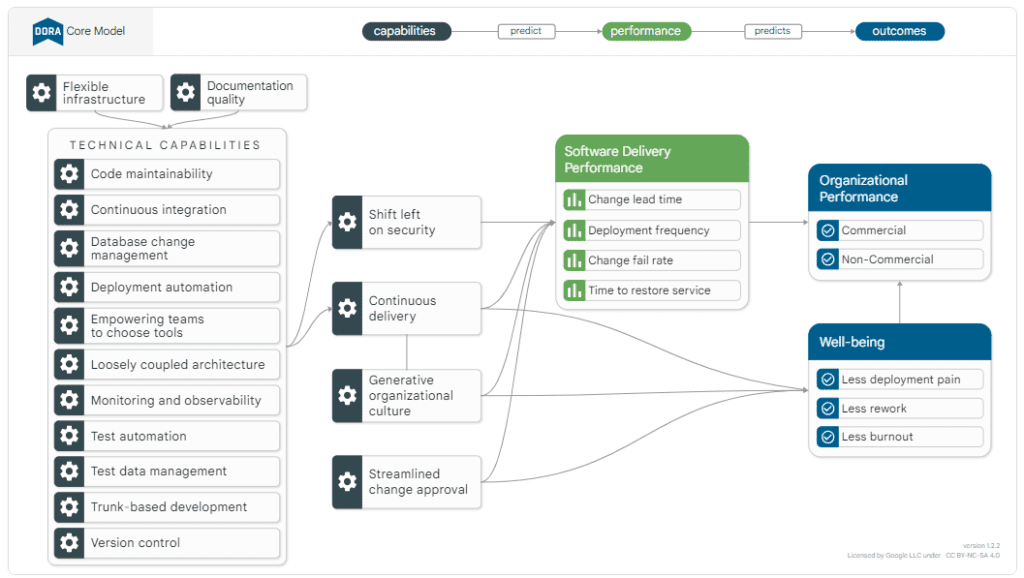
As quarto métricas definidas através do livro Accelerate são: Lead time for change, Deployment Frequency, Mean time to restore e Change Failure Rate. Essas métricas são estruturadas de uma maneira inteligente, fruto de muita pesquisa.
Por exemplo, há uma métrica de frequencia de deployments. Se uma empresa focar apenas nesse indicador ele pode entregar muitos bugs. Por conta disso há outro indicador, o Change Failure Rate que dá a razão entre deploys (entregas) e bugs (falhas). Simplemente não é possível olhar apenas um indicador como driver e ignorar os demais.
Entendendo as métricas
DF – Deployment Frequency
Essa métrica lida com a frequencia dos deployments. Ela tem como premissa que quanto mais deployments e quanto mais rápidos, melhor para a entrega de valor para a empresa. Há uma conexão direta entre o deployment frequency e práticas de integração contínua. Quanto mais automatizado for o processo de entrega dos sistemas desenvolvidos, melhor. Mas além disso, essa métrica também tem na sua alma o conceito de Fail Fast (falhar rápido). Quando menor a funcionalidade mais rápido é sua inclusão em produção.
Uma empresa com muitas squads (ou o nome que preferir dar para os times que desenvolvem) terá diferentes níveis de maturidade para questões como essa, com frequencias mais altas que outras. É importante lidar de modo inteligente com essa métrica ao invés de simplesmente comparar times e gerar desconfortos gratuitos, já que os times sempre têm suas particularidades.
LT – Lead time for change
Essa métrica lida com todo o processo de uma mudança. Uma vez registrada a mudança o lead time se inicia, e ele só termina quando ela entra efetivamente em produção. Trata-se de uma visão muito abrangente que pode necessitar de ferramentas de terceiros, desenvolvimento sob medida, dashboards, etc. para ter esse nível de controle.
Não é incomum um aumento do uso de feature tuggle, ou seja, funcionalidades que estão no código produtivo mas não são acessíveis para o usuário final num primeiro momento. Na minha visão não há nesse caso uma efetiva entrega de valor, uma vez que o usuário final não se beneficia dele. Mas isso não torna a métrica menos importante.
Como essa métrica é muito abrangente não é incomum encontrar variações dela. Algumas empresas trabalham considerando o ciclo completo, desde o pedido da mudança até a entrada do código em produção; outras apenas após o primeiro commit e assim por diante. Acho que ambas as visões têm sua importancia.
Por fim, entendo que a informação mais relevante que essa métrica dá é qual a real capacidade de entrega do time de TI em contraste ao time to market, dando clareza de como a TI é diferencial competitivo para a companhia.
MTTR – Mean time to restore
Essa métrica tem uma visão direcionada para a sustentação dos serviços em produção. Um determinado produto quando tem algum incidente atrapalha o usuário final, os usuário de backoffice envolvidos e a TI que tem que lidar com a questão. Ter produtos com poucas falhas indica que ele é maduro e que a equipe é boa tornando-o estável. Se, além disso, o produto tiver índices de deployment frequency bons, trata-se de algo com excelência.
O conceito desse indicador é medir o tempo de um incidente até sua implantação em solução. Nota-se que se a causa raiz do incidente exigir uma mudança, haverá algo para a medição do lead time for change; e quando for colocada em produção moverá o indicador de deployment frequency.
Entretanto, pode ser necessário observar outros pontos como a disponibilidade proativa de produtos em produção, para que sejá possível criar essa medida. Além disso é comum medir o Mean Time Between Failures, ou seja, o tempo médio entre um falha e outra.
CRF – Change Failure Rate
Essa métrica está ligada a estabilidade, indicando a relação entre mudanças entregues e as falhas relacionadas. Quando essa taxa é baixa o processo de mudanças está funcionando bem, com poucas falhas e com boa capacidade de entrega.
Equipes que monitoram e agem rapidamente resolvendo as falha costumam ter uma cultura orientada a qualidade e melhoria contínua. Note como todas as métricas se conectam belamente.
Conclusão de DORA Metrics
Por fim, o framework DORA Metrics destaca-se como uma abordagem abrangente e estratégica para avaliar o desempenho das equipes de desenvolvimento e operações. As quatro métricas essenciais – Deployment Frequency, Lead time for change, Mean time to restore e Change Failure Rate – não apenas oferecem insights valiosos sobre a eficácia operacional, mas também estão intrinsecamente interconectadas. Assim, ao adotar essas métricas, as organizações podem alcançar uma compreensão holística de seu ciclo de vida de desenvolvimento, promovendo uma cultura enraizada em qualidade, agilidade e melhoria contínua.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
