
Essa é uma importante ferramenta quando falamos de bigdata, engenharia de dados, e afins. Ela é útil para agendar, definir e executar fluxos de trabalho, simples ou complexos. Assim, o básico do Apache Airflow vai falar sobre seus conceitos, arquitetura, dags e dar um exemplo em python sobre como construí-la.
Então, aqui no blog temos divesos artigos que falam sobre kubernetes, arquitetura de software, DDD, dados, gestão, entre outros. É possível que esses artigos possam ser interessantes para a leitura de O básico de Apache Airflow, embora não sejam requisitos.
- Banco de dados: Teorema CAP
- Os 14 tipos de bancos de dados
- Arquitetura Lambda e Arquitetura Kappa
- O Essencial do Hadoop
Sumário
- Apache Airflow
- O que é DAG
- Conhecendo uma DAG em python
- Conclusão de O básico de Apache Airflow
- Porque você precisa saber HTTP
- Arquitetura Lambda e Arquitetura Kappa
- Bounded Contexts de dependência mútua
- Principais Conceitos de Python
- Top 25 Ferramentas do Hadoop
- Os 14 tipos de bancos de dados
- Formatos de serialização para bigdata
- Entendendo o Apache Spark
Apache Airflow
Então, o Apache Airflow é uma ferramenta opensource criada para AirBNB em 2014 que hoje é mantido pela Apache Foundation. Assim, ela é responsável por orquestrar workflows (fluxos de trabalho) voltadas para dados. Além disso ela tem uma estrutura para agendamento desses fluxos.
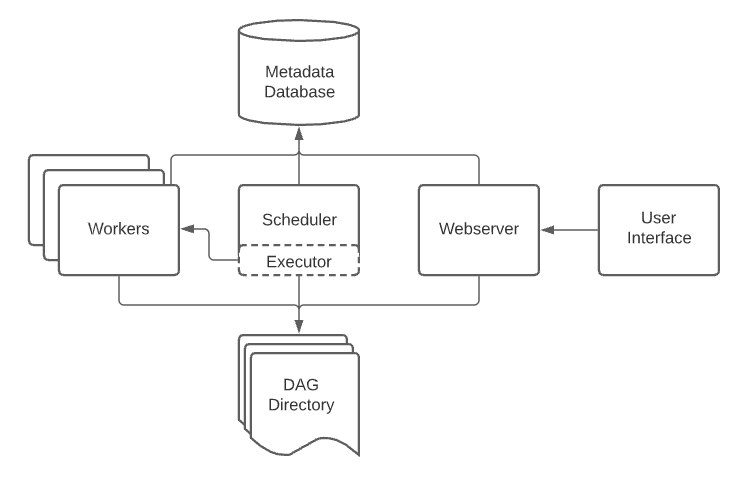
Desse modo, o Airflow é robusto por ter uma arquitetura resiliente e que suporta fluxos complexos com quantidades enormes de dados. Então, ele possui uma interface gráfica (User Interface ou UI) que interage todo o momento com o WebServer, facilitando a manipulação dos workflows. Assim, também possui um banco de dados de metadados (Metadata Database) que armazena informações relevantes das DAGs (que serão explicadas na continuidade do artigo). Além disso, o airflow tem também o Scheduler, responsável por agendas a execução das dags com base nos metadados.
E por fim, o Executor é o responsável por definir a forma de execução da computação definida para a dag. Então há os tipos LocalExecutor, SequentialExecutor e CeleryExecutor que permitem execuções seriais ou paralelas das tarefas. E há também os Workers, são os locais onde de fato as computações são realizadas, seguindo as definições do Executor.
O que é DAG
DAG é o acrônico para Directed Acyclic Graph (Grafo Acíclico Direcionado). Esse é um diagrama representado por grafos onde cada nó só pode ter apontamentos para um sentido, até que ele se termine. Trata-se de um fluxo linear, que pode ter bifurcações e paralelismos, mas nunca loops ou retornos.
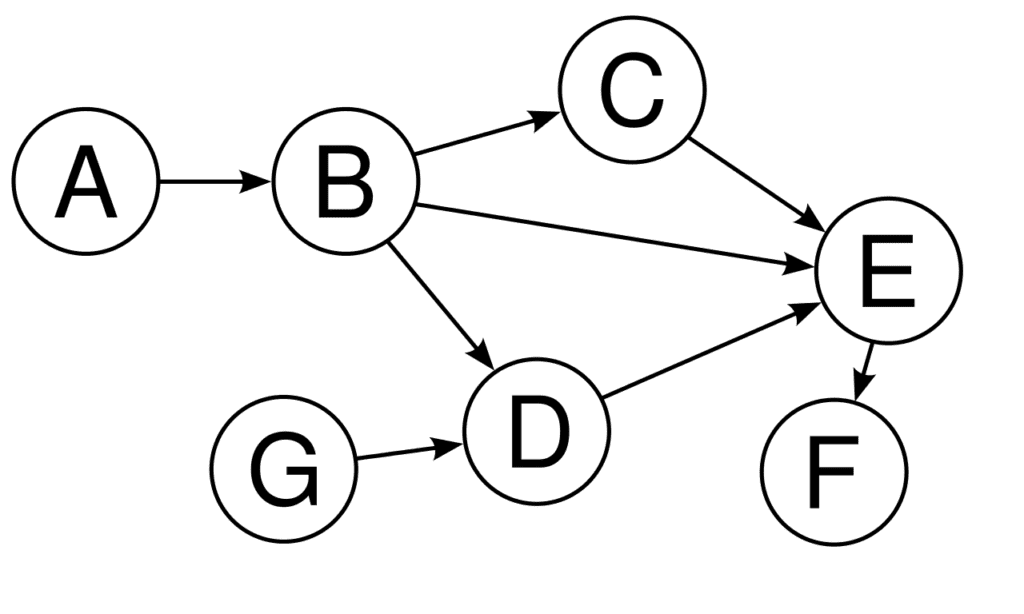
O básico do Apache Airflow inclui destacar que há uma estrutura que suporta a criação de novas DAGs em python, a possibilidade de configurações e execuções, bem como o seu correto agendamento. As dags são fundamentais para o Apache Airflow e para outros orquestradores, como o Apache Oozie.
No Airflow as DAGs possuem operadores, que são estruturas que dão funcionalidades especiais para o fluxo. Por exemplo, se o fluxo tiver que utilizar um código em Python, ela utilizará o PythonOperator. Já para acessar banco de dados pode-se utilizar SQLAlchemyOperator, para Shell BashOperator, para Docker DockerOperator, entre vários outros. Além disso, se necessário, é possível expandir a ferramenta criando novos Operators.
Além disso, há nas DAGs as Tasks (Tarefas) que são as ações que efetivamente realizam computação. Essas são as unidades mais específicas de um fluxo. Alguns exemplos:
- Obter dados sobre queimadas no Brasil
- Processar Somatório de todos os sinistros de Roubo de carro em cidades de até 500.000 habitantes
- Enviar um e-mail informando um determinado resultado
- Enviar uma notificação no Slack
Conhecendo uma DAG em python
Entre outras coisas, é muito importante entender de python para construir DAGs no Airflow. O exemplo a seguir é de uma aplicação que obtem dados de queimadas no Brasil de maneira fictícia, obtem a média e salva em um arquivo CSV.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.dummy_operator import DummyOperator
import pandas as pd
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 7, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'queimadas_brasil_dag',
default_args=default_args,
description='DAG to fetch Brazil wildfires data and perform some operations',
schedule_interval=timedelta(days=1),
)
def fetch_wildfires_data(**kwargs):
# Example of creating a dummy dataframe for illustration purposes only:
data = {
'date': ['2023-07-21', '2023-07-22'],
'wildfires': [500, 750]
}
df = pd.DataFrame(data)
kwargs['ti'].xcom_push(key='wildfires_data', value=df)
def process_wildfires_data(**kwargs):
df = kwargs['ti'].xcom_pull(key='wildfires_data')
average_wildfires = df['wildfires'].mean()
kwargs['ti'].xcom_push(key='average_wildfires', value=average_wildfires)
def save_results_to_csv(**kwargs):
average_wildfires = kwargs['ti'].xcom_pull(key='average_wildfires')
# Create a dataframe to save the results to a CSV file
results = {
'date': [datetime.now().strftime('%Y-%m-%d')],
'average_wildfires': [average_wildfires]
}
df_results = pd.DataFrame(results)
df_results.to_csv('/path/to/results_wildfires.csv', index=False)
with dag:
start = DummyOperator(task_id='start')
fetch_data_task = PythonOperator(
task_id='fetch_wildfires_data',
python_callable=fetch_wildfires_data,
provide_context=True,
)
process_data_task = PythonOperator(
task_id='process_wildfires_data',
python_callable=process_wildfires_data,
provide_context=True,
)
save_to_csv_task = PythonOperator(
task_id='save_results_to_csv',
python_callable=save_results_to_csv,
provide_context=True,
)
end = DummyOperator(task_id='end')
# Set the task dependencies
start >> fetch_data_task >> process_data_task >> save_to_csv_task >> endConclusão de O básico de Apache Airflow
O Apache Airflow é uma ferramenta notável por sua flexibilidade e por trabalhar diretamente com python, que facilita bastante. O orquestrador de workflows de dados trabalha com diversas dags para cumprir o seu propósito. O artigo oferece uma visão geral tanto do conceito quanto de uma criação real em python.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
