
Imagine um vasto labirinto de informações, onde cada clique é uma passagem para uma infinidade de possibilidades. Então, este é o mundo do Hipertexto, uma teia interconectada que molda a internet que conhecemos hoje. Assim, a base para essa complexa rede é o protocolo HTTP, o HyperText Transfer Protocol. Então pergunto: Porque você precisa saber HTTP?
A evolução desse protocolo, desde sua origem na HTTP 0.9 até as mais recentes versões 2 e 3, desempenha um papel crucial na otimização da velocidade, segurança e na experiência do usuário online. Ademais, este post explora as nuances de cada versão do HTTP, falando sobre seus recursos, limitações e impacto na navegação web. Por fim, vamos ao longo desse artigo entender por que todo dev ou ops precisam dominar esse bicho.
Sumário
Contextualizando
Hipertexto
Me lembro de quando era criança e jogava RPG quando encontrei um livro que parecia seguir essa temática. Não me recordo do nome, mas lembro que era assim: Você lia algumas páginas e encontrava uma pergunta, por exemplo: “Se deseja que fulano ataque o monstro, vá para a página 50; se deseja que fulano corra do monstro, vá para a página 90.” Esse livro era dinâmico, oferecendo uma grande variedade de finais possíveis: era incrível!
Essa foi uma das minhas primeiras experiências com hipertexto. A ideia dos links de internet é o que constrói esse vasto mar de possibilidades. Imagine uma página com 10 links, sendo 5 internos (para o mesmo domínio) e 5 externos (para outros domínios). Cada um desses links contém mais links internos e externos, criando um grau de interconectividade praticamente infinito.
O protocolo HTTP, ou HyperText Transfer Protocol, lida do melhor modo com o hipertexto, se comparado aos demais protocolos. Já a linguagem HTML, ou HyperText Markup Language, desempenha um papel fundamental, estruturando e definindo como os textos se comportam nessa mídia.
Modelo OSI e Modelo TCP/IP
Seguindo esse raciocínio, para uma mensagem chegar de um computador A para um computador B, em redes abertas, foi necessário muito esforço no sentido de estabelecer padrões. A ISO criou, então, um modelo teórico chamado Open System Interconnection, que é a referência para as redes até hoje. Acontece que esse modelo é teórico e a medida que as redes foram evoluindo percepções práticas foram surguindo e gerando leves modificações na interpretação dele, criando assim o modelo TCP/IP.
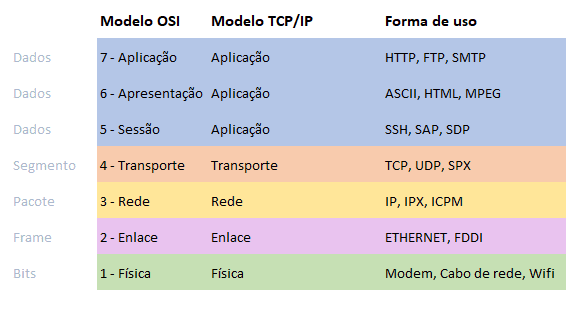
A camada de aplicação inicia a requisição HTTP, que por sua vez, ganha informações relevantes sobre a estratégia de transporte. Após, com TCP, ganha endereços de origem, destino e rotas na camada 3. E então, ganha informação do endereço físico como MAC Address dos dispositivos envolvidos. E por fim envia-se a mensagem a um meio físico, como um WIFI. A partir daí a mensagem passa por muitos lugares, de acordo com o roteamento definido e com as características práticas do transporte. Por fim chega ao seu destino, que faz o trabalho inverso, da camada 1 até a 7 OSI.
Uma vez recebida a mensagem é um problema do protocolo HTTP oferecer resposta (Response) à Request feita através de uma nova mensagem que tem como destinatário quem enviou a mensagem original.
HTTP 0.9 – a origem
A primeira versão publicada como oficial do protocolo é a 0.9, lançada em 1991. Ela foi realmente muito básica e tinha pouquissimos recursos. Por exemplo, só existia o verbo GET. O HTTP 0.9 transmite mensagens de forma simples, sem cabeçalho, status ou metadados.
HTTP 1.0 – o baby
Já a versão 1.0 veio com um pouco mais de complexidade, embora seja pouco para nossos padrões de hoje em dia. Ela passou a suportar os verbos GET, HEAD, POST e PUT. Mas note que não existir o delete nesse momento, por exemplo.
Além disso, o HTTP/1.0 foi o primeiro a implementar cabeçalhos de resposta, permitindo que servidores enviassem informações adicionais, como status de conexão, tipo de conteúdo ou data de modificação. Por exemplo, um cabeçalho ‘Content-Type’ informa ao navegador o tipo do arquivo recebido, como HTML, imagem, etc.
Ao abrir uma página com imagens, essa versão apenas realizava o download de cada imagem após baixar toda a página, uma a uma. Isso ocorre porque não havia uma conexão persistente que associava os diversos recursos. Quem viveu esse tempo lembra bem, através de sua internet discada.
HTTP 1.1 – o mais utilizado
Essa versão é o divisor de águas, sendo até hoje a versão mais utilizada. Criada em 1997 ela introduziu o conceito de conexões persistentes, permitindo ao cliente manter uma conexão aberta com o servidor após a primeira solicitação. Isso fez com que menos cabeçalhos de controle fossem carregados a cada conexão e permitiu um download mais rápido dos elementos da página. Também vale destacar que nessa época as páginas foram ganhando cada vez mais elementos com gifs animados, htmls pesados (CSS práticamente não era usado, nascido em 1996) .
Além disso, o HTTP 1.1 tem os seguintes verbos GET, POST, PUT, DELETE, HEAD e OPTIONS:
- GET: Solicita um recurso específico de um servidor.
- POST: Submete dados para serem processados a um recurso identificado pelo URI.
- HEAD: Igual ao GET, mas sem o corpo da resposta. Útil para verificar cabeçalhos.
- PUT: Envia um arquivo para o servidor para ser armazenado no URI fornecido.
- DELETE: Remove um recurso identificado por um URI.
- CONNECT: Converte a solicitação de conexão para um túnel TCP/IP.
- OPTIONS: Retorna os métodos HTTP que o servidor suporta para o URI especificado.
- TRACE: Executa um teste de loop de volta no caminho para o recurso de destino.
A Anatomia do HTTP
A comunicação HTTP se dá sempre por requisições (requests) e respostas (responses). O responsável por construir as requisições é uma aplicação cliente, seja um navegador, um postman, curl ou uma aplicação desenvolvida manualmente. Ela se responsabiliza por construir um pedido coerente sob pena do servidor recusar o pedido.
A Request tem: linha de pedido, cabeçalho e corpo da requisição. A primeira e segunda linha do exemplo abaixo é o pedido, onde é especificado o verbo, o recurso e a versão do protocolo em que se está trabalhando. A partir dessa linha estão os cabeçalhos: são muitos os tipos possíveis que ajudam a especificar melhor a solicitação. Por fim, após uma linha vazia segue a mensagem.
No exemplo em questão há um formulário HTML faz um POST para /submit_form do site www.exemplo.com com o nome, idade e passaporte, todos os texto puro (mas poderia ser em xml, json, yaml ou o que quiser, respeitando as limitações do protocolo).
POST /submit_form HTTP/1.1
Host: www.exemplo.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 57
nome=João%20da%20Silva&idade=30&passaporte=ABC12345Após a requisição o servidor processa e oferece uma resposta com um padrão semelhante. Ela tem uma linha de status, o cabeçalho e o corpo. A linha de cabeçalho possui a versão, um código que indica o que foi feito com a requisição e um texto que explica o status. No caso, 200 indica que foi processado com sucesso.
Depois aparecem os cabeçalhos, como server, content-lenght, etc. Por fim, após a linha vazia há a resposta, que no caso é uma página HTML simples.
HTTP/1.1 200 OK
Date: Fri, 27 Oct 2023 08:30:15 GMT
Server: Apache
Content-Length: 37
Content-Type: text/html
<html>Seus dados foram recebidos.</html>HTTP 2 – o bom
O HTTP 2.0 adotou a comunicação binária: um real avanço. Através da multiplexação, múltiplas requisições podem ser transmitidas simultaneamente em um mesmo canal de conexão. Esse processo de comunicação binária otimiza o uso de recursos e reduz a latência para a transmissão dos dados. Outro recurso interessante é o Server Push. Com essa técnicologia o servidor pode enviar conteúdos para o cliente sem uma request específica.
Outro ponto de destaque é a obrigatoriedade de criptografia nas conexões em HTTP. Antes da versão 2, o HTTP poderia ser envelopado utilizando TLS no que é conhecido como SSL (Secure Socket Layer). Isso modifica a forma escrita do protocolo para HTTPS. A versão 2 simplesmente torna essa prática obrigatória. Se você está por dentro de SEO deve saber que o google e outros motores de busca ignoram sites sem esse tipo de proteção.
HTTP 3 – o excelente
Ao contrário das versões anteriores que utilizavam TCP como protocolo de transporte, essa versão utiliza um protocolo chamado QUIC (Quick UDP Internet Connections). Trata-se de uma variação do protocolo para suportar contínuas mudanças de rede, algo comum com aparelhos celulares. O UDP realiza conexões multiplexadas, permitindo assim, que vários pedidos sejam transmitidos simultaneamente por uma única conexão. Isso reduz a latência, melhorando a eficiência em comparação com o TCP usado anteriormente no HTTP/1 e HTTP/2. Além disso, o HTTP/3 tende a minimizar problemas estruturais nas versões anteriores (como o o head-of-line blocking, uma situação onde uma requisição lenta retarda todas as outras)
Conclusão de Porque você precisa saber HTTP
Então, o HTTP é a base da World Wide Web. Assim, desde suas origens simples na HTTP 0.9 até a complexidade robusta da HTTP 3, essa evolução trouxe inovações substanciais que impactaram a forma como interagimos e nos conectamos online. Desse modo, à medida que avançamos, é fundamental acompanhar essa evolução para compreender as tendências atuais e futuras na navegação na web. O protocolo HTTP, em sua jornada de evolução, continua a moldar o futuro do ambiente digital, proporcionando uma experiência web mais rápida, segura e eficiente para todos os usuários.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
