
Aplicações modernas são vivas, complexas e difíceis de prever. Então, elas não rodam sozinhas, isoladas, como antigamente: Estão espalhadas em APIs, filas, microsserviços, lambdas, e se comunicam em tempo real, com múltiplas camadas de abstração e infraestrutura. Assim, nesse cenário, confiar apenas em logs locais ou na sorte virou um ato de irresponsabilidade técnica. Em vez de esperar algo quebrar, você precisa ser capaz de entender o que está acontecendo enquanto está acontecendo. Essa é a essência da observabilidade. Mais do que uma buzzword, ela é o que permite que você saiba se sua aplicação está saudável, onde estão os gargalos, quais usuários estão sendo afetados, e até como melhorar a experiência do cliente. No artigo Observabilidade, vamos entender o que é observabilidade, de onde ela vem, seus pilares, e como adotá-la com inteligência e arquitetura limpa.
Mas, além do artigo Observabilidade, aqui no blog também temos diversos outros artigos sobre kubernetes, desenvolvimento, gestão, devops, etc. Veja alguns exemplos: Diferenças entre Paradigmas, Axiomas e Hipóteses, Desenvolver na empresa ou comprar pronto, Fuja da otimização prematura, entre outros.
Sumário
- A origem do conceito de observabilidade
- Os pilares da observabilidade
- OpenTelemetry
- OpenAPM
- Conclusão de Observabilidade
- Os 14 tipos de bancos de dados
- Teoria versus Prática
- Sincronizando Gitea com Github
- Porque você já deveria estar usando Hashicorp Consul?
- O que é a TAC?
- Não basta ser, tem que parecer
- Como é a estrutura de valores em uma economia?
- DORA Metrics
A origem do conceito de observabilidade
Você fez o deploy da sua aplicação, tudo verdinho na pipeline de CI/CD, e a produção está rodando. Agora é torcer? Não. Agora é observar. Porque algo vai falhar alguma hora. É por isso que observabilidade virou chave na arquitetura moderna: sem ela, você está operando no escuro, sem quaisquer aparelhos.
A ideia de observabilidade vem da teoria de controle de sistemas. Originalmente, trata-se da capacidade de entender o estado interno de um sistema apenas pelas saídas que ele gera. Quando o conceito migrou para o universo do software, ele se transformou em algo mais prático: a capacidade de entender o comportamento da sua aplicação em tempo real, mesmo quando ela está distribuída em vários serviços, filas, integrações e chamadas em cadeia.
Em uma aplicação monolítica, a vida costuma ser mais simples. Você tem um arquivo de log central, talvez alguns eventos do sistema operacional, e tudo está ali, no mesmo lugar. Mas quando migramos para microserviços e arquiteturas distribuídas, a realidade muda. Cada serviço tem sua própria forma de gerar logs, métricas e eventos. E pior: muitas vezes, uma requisição passa por vários desses serviços antes de dar erro. Entender o que está acontecendo passa a exigir mais do que apenas um grep no log. É aí que entra a observabilidade moderna.
O que é observabilidade?
Observabilidade é uma característica da aplicação. Não é uma ferramenta, não é um dashboard bonito e nem um botão mágico. É a capacidade de saber o que está acontecendo com o sistema sem precisar perguntar para o cliente. Se a única forma de descobrir que algo deu errado é quando o suporte recebe uma ligação, então você não tem observabilidade. O que você tem é uma caixa-preta rodando em produção, e isso é um risco grave.
Mas observabilidade vai além de detectar erros. Ela também permite entender padrões de uso, identificar gargalos, sugerir melhorias na jornada do cliente e até encontrar oportunidades de negócio. É a sua lente sobre o sistema. A partir dela, você pode tomar decisões técnicas e estratégicas com base em dados reais, coletados em tempo real, a partir do comportamento natural da aplicação em produção.
Observabilidade e Monitoramento
Existe uma confusão comum entre monitoramento e observabilidade. Monitoramento é reativo. Ele responde perguntas como “está funcionando?” e aciona alertas quando algo sai do normal. Observabilidade, por outro lado, é investigativa. Ela responde “por que não está funcionando?” e permite que você explore causas raízes e impactos secundários.
Enquanto o monitoramento usa regras e limites predefinidos, a observabilidade coleta dados abertos e ricos, permitindo analisar contextos que você nem sabia que precisava. No fundo, monitoramento é um subconjunto da observabilidade. Ter observabilidade te dá as ferramentas para fazer um bom monitoramento, mas o inverso nem sempre é verdade.
Os pilares da observabilidade
A observabilidade se sustenta em três pilares: logs, métricas e traces. Eles se complementam e, juntos, fornecem uma visão do que está acontecendo no seu sistema.
Log
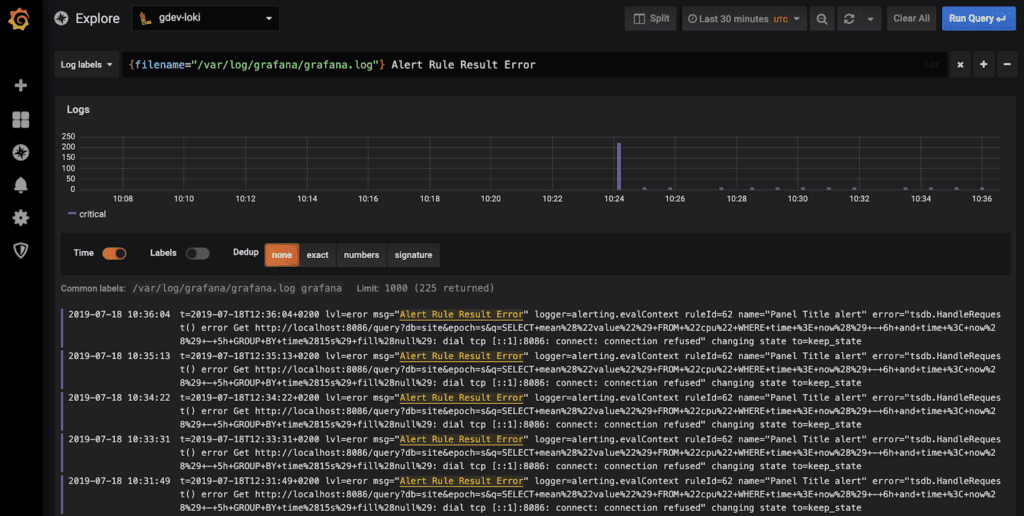
Logs são eventos registrados pela aplicação. Eles costumam estar em formato textual e descrevem comportamentos, exceções, falhas, avisos ou qualquer tipo de evento relevante. Em um sistema distribuído, abrir log por log manualmente é inviável. Por isso, usamos soluções que coletam, centralizam e indexam esses registros.
A ELK Stack (ElasticSearch, LogStash e Kibana) se tornou uma das mais populares para esse tipo de trabalho. ElasticSearch, baseado no Lucene, permite buscas rápidas em grandes volumes de texto, enquanto LogStash coleta e transforma os logs, e o Kibana os exibe de forma visual. Outras alternativas como Loki, da Grafana Labs, ou Graylog também são bastante usadas, cada uma com seus diferenciais particulartes.
Métricas
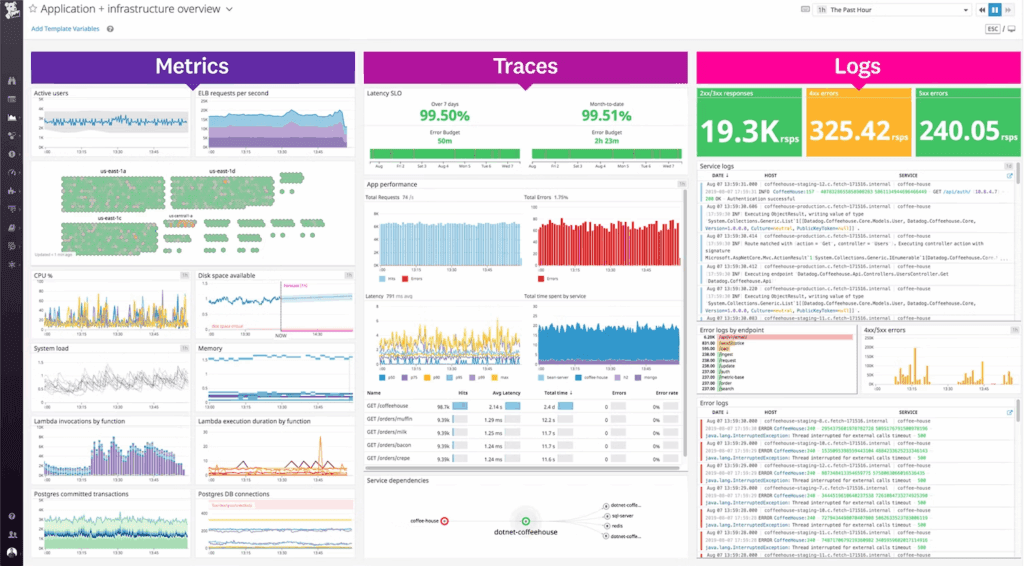
Métricas são números. Elas representam grandezas medidas ao longo do tempo: uso de CPU, memória, quantidade de requisições, taxa de erros por segundo, entre outras. Elas também podem ser métricas de negócio, como número de vendas, novos usuários cadastrados ou conversões no funil de compra. Essa separação entre métricas técnicas e métricas de negócio é fundamental para enxergar o sistema de forma completa.
O Prometheus é uma das ferramentas OpenSource mais populares para coleta de métricas em tempo real. Ele funciona bem com o Grafana, que é usado para criar dashboards que ajudam a visualizar os dados de forma rápida. Outras ferramentas como NewRelic, DataDog e InfluxDB também são amplamente utilizadas, dependendo do seu orçamento, volume de dados e preferências técnicas.
Trace
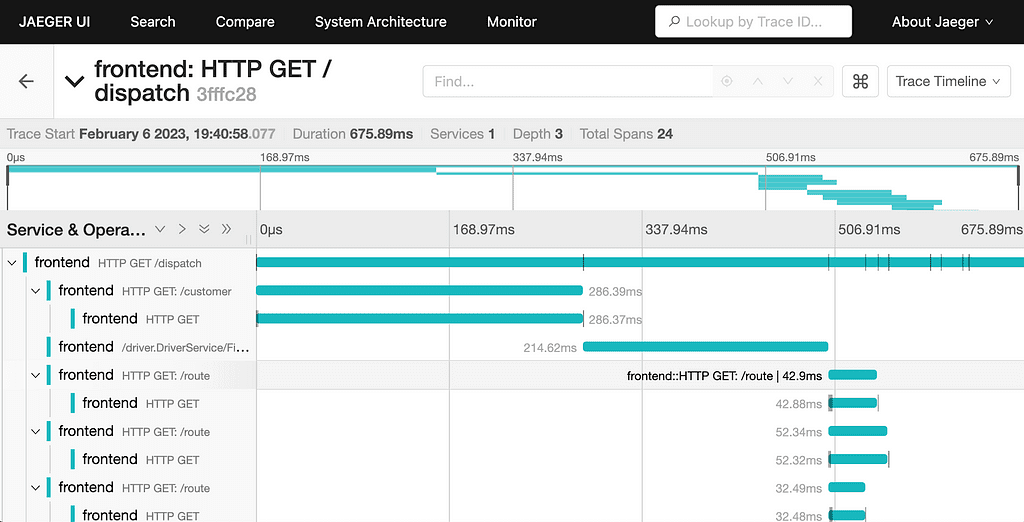
Traces são responsáveis por rastrear o caminho de uma requisição ao longo de múltiplos serviços. Quando um cliente inicia uma ação, como clicar em “comprar”, esse comando pode passar por APIs, serviços internos, filas de processamento, e voltar. Os traces permitem enxergar esse caminho completo.
Para isso, cada requisição recebe um identificador único, chamado correlation ID, que é repassado entre os serviços e permite reconstruir a trilha exata de execução. Essa prática é fundamental para identificar gargalos e localizar erros em sistemas distribuídos. Ferramentas como o Jaeger e o Zipkin são líderes nessa área.
OpenTelemetry
O OpenTelemetry, ou Otel, surgiu como uma resposta ao caos de ferramentas e formatos no universo da observabilidade. Com tantas soluções disponíveis, cada uma com seus próprios SDKs, formatos e APIs, o risco de se tornar refém de uma única plataforma é enorme. Ao padronizar a forma como logs, métricas e traces são coletados e exportados, o Otel permite que você escreva uma vez e envie os dados para qualquer destino: seja Jaeger, Prometheus, ElasticSearch, DataDog, NewRelic ou qualquer outro. Com isso, ele reduz drasticamente o vendor lock-in, dando liberdade para evoluir sua stack conforme necessidade, sem reescrever a aplicação inteira.
Além de liberdade, o OpenTelemetry ajuda na organização, embora não resolva. Integrá-lo à sua aplicação pode auxliar a seguir princípios da Clean Architecture, isolando o código de infraestrutura do código de negócio. Em vez de poluir seus serviços com chamadas diretas a SDKs proprietários, você abstrai a instrumentação e mantém seu domínio limpo. Isso facilita testes, reduz acoplamento e torna seu sistema mais flexível. A observabilidade deixa de ser (na medida do possível) uma gambiarra embutida na lógica e passa a ser um aspecto bem definido da arquitetura.
O Otel também é open source e mantido pela CNCF, o que garante longevidade e compatibilidade com todo o ecossistema cloud native. Com suporte a múltiplas linguagens, coleta automática, sidecars para Kubernetes e integração nativa com ferramentas de visualização, ele se tornou o padrão de fato para quem quer observabilidade moderna e sustentável. Em vez de prender seu sistema a uma ferramenta, o Otel te dá poder de escolha — e, mais importante, te dá um caminho para crescer sem bagunça.
OpenAPM
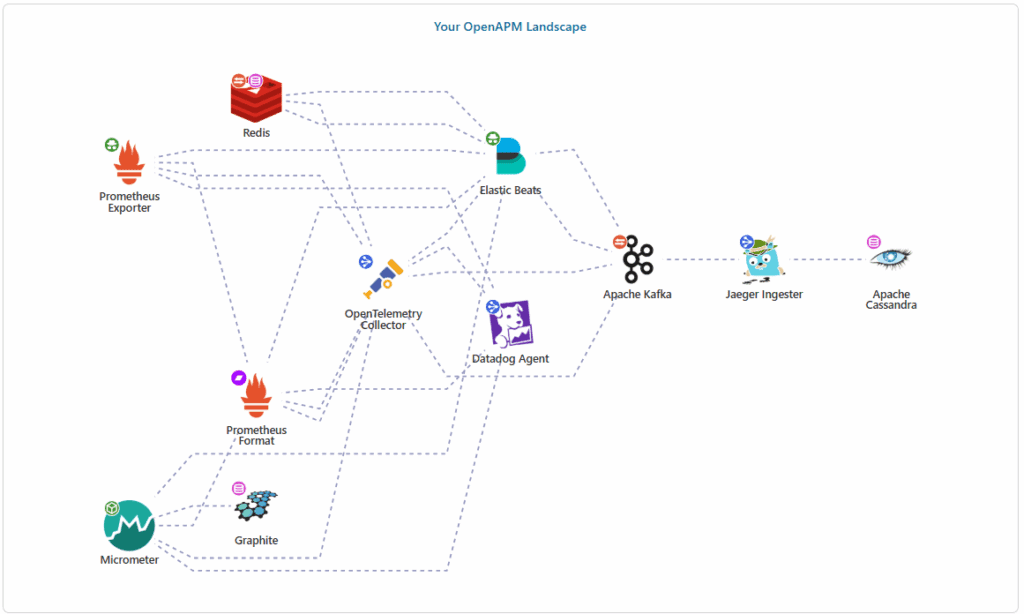
Seu sistema em particular pode lidar com múltiplas estruturas e ferramentas de observabilidade. Assim, o OpenAPM é um ambiente que te ajuda a estruturar e organizar tudo isso. Então, no site da OpenAPM ele apresenta um landscape com muitas e muitas ferramentas desse contexto. Desse modo você pode adiciona-las e um diagrama é montado automaticamente te orientando sobre como organizar os fluxos relacionados a observabilidade.
Conclusão de Observabilidade
Observabilidade é a base para operar sistemas modernos com confiança. Assim, em um cenário distribuído, cheio de integrações, filas e serviços, não basta saber que algo quebrou: é preciso entender o porquê, onde e com que impacto. Então, ao adotar uma estratégia sólida de logs, métricas e traces, e utilizar ferramentas como OpenTelemetry para reduzir acoplamentos e evitar dependência de fornecedores, você transforma caos em clareza.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
