
A evolução para arquiteturas de software de larga escala e orientadas a eventos revelou as limitações dos message brokers tradicionais, como o RabbitMQ. Enquanto a comunicação assíncrona é fundamental para o desacoplamento de microserviços, o throughput exigido por empresas de escala global demanda algo diferente. Assim, uma plataforma distribuída capaz de persistir e processar eventos de forma massiva. Então, é neste contexto que o Apache Kafka se estabelece, transformando o fluxo de dados em um log de eventos durável e escalável. O objetivo do artigo Casos de uso do Apache Kafka é explorar como essa arquitetura robusta e escalável se aplica com casos de uso.
Mas, além do artigo Casos de uso do Apache Kafka, aqui no blog também temos diversos outros artigos sobre kubernetes, desenvolvimento, gestão, devops, etc. Veja alguns exemplos: Diferenças entre Paradigmas, Axiomas e Hipóteses, Desenvolver na empresa ou comprar pronto, Fuja da otimização prematura, entre outros.
Sumário
- Os Message Brokers
- Os tipos de mensagem
- Compreendendo o Apache Kafka
- Casos de uso do Apache Kafka
- 1. Integração de Sistemas (Event Streaming)
- 2. Comunicação entre Microserviços e sistemas distintos em tempo real.
- 3. Agregação de Logs e Observabilidade
- 4. Processamento de Dados em Tempo Real (Streaming Analytics)
- 5. IoT e Sensores
- 6. ETL em Tempo Real (Data Ingestion)
- 7. Event Sourcing e CQRS
- 8. Sincronização de Bancos de Dados
- 9. Arquiteturas Multi-Cloud
- 10. Data Mesh
- Conclusão de Casos de uso do Apache Kafka
- Compras Inteligentes em TI
- Como exibir uma lista de um site SharePoint em outro site SharePoint?
- Consensus Protocol: o que você tem que saber (dev e ops)
- 7 APIs públicas, gratuitas e de qualidade
- Notification Pattern no DDD
- O essencial de GIT
- Mediator Pattern no Domain Driven Design
- API HTTP, REST ou RESTFul
Os Message Brokers
Quando falamos de aplicações de larga escala modernas nos deparamos com message brokers que intermediam as comunicações gerando um ambiente escalável sob vários pontos de vista. O primeiro é do negócio, que se definido numa estrutura de domínios, contextos e afins, processos podem ser construídos com equipes independentes; o segundo é do ponto de vista da tecnologia do desenvolvimento que tem arquitetura altamente modular; e o terceiro é o ponto de vista da infraestrutura onde os serviços bem como as mensagens são escaláveis horizontal ou verticalmente. De certo modo o Domain Drivem Design é a cola conceitual que gera esse modelo.
Para que tudo isso seja possível uma arquitetura orientada a eventos ganha protagonismo. Uma estrutura modularizada faz seu trabalho, dispara eventos, cabendo a outra equipe / sistema absorver esse evento para dar continuidade à suas ações de entrega de valor.
O RabbitMQ
O RabbitMQ é um message broker muito utilizado e fácil de trabalhar. Então, ele foi construído sob uma linguagem estruturada para lidar com green threads: rápido e sem trocas significativas de contextos do processador. Ele também usa um protocolo próprio, o AMQP (Advanced Message Queuing Protocol), que estrutura o formato das rotas, da mensagem, etc.
Agora, podemos categorizar o RabbitMQ como um broker tradicional, que prioriza a consistência e a segurança. Ele tipicamente, em situações normais, lida com o volume de 20000 a 50000 mensagens por segundo. Mas quando ajustado pode lidar com 100000. Embora esse volume seja muito significativo para a maior parte dos sistemas, pode ser um limitador para aplicativos de escala global como Uber, Netflix ou Linkedin.
Os tipos de mensagem
A mensagem é a parte da comunicação que tem a principal substância, onde há significado e significante, onde há valor real para os usuários. Ela pode ter características diferentes que podem mudar a forma de pensar um sistema. O primeiro tipo é o Event Notification. Ele considera que a mensagem é uma informação curta, não detalhada e descartável. Um pedido aprovado num e-commerce poderia ser o seguinte:
{ "pedido": 123, "status": "aprovado" }Mas há uma outra abordagem onde a mensagem é rica e completa, com detalhes. Ela é chamada de Event Carried State Transfer ou, mais popularmente, um streaming de dados. O JSON a seguir representa o mesmo pedido aprovado num e-commerce, mas em detalhes.
{
"pedido": 123,
"data": "2025-10-27T14:30:00Z",
"status": "aprovado",
"cliente": {
"id": 987,
"nome": "Thiago Anselme",
"email": "[email protected]",
"telefone": "+55 21 99999-8888",
"endereco": {
"rua": "Rua das Palmeiras, 120",
"cidade": "Petrópolis",
"estado": "RJ",
"cep": "25600-000"
}
},
"itens": [
{
"produto_id": 1,
"nome": "Memória RAM DDR4 8GB",
"quantidade": 2,
"preco_unitario": 249.90,
"categoria": "Hardware"
},
{
"produto_id": 2,
"nome": "Gabinete Gamer Mid Tower",
"quantidade": 1,
"preco_unitario": 399.00,
"categoria": "Hardware"
},
{
"produto_id": 3,
"nome": "Monitor LED 24'' Full HD",
"quantidade": 1,
"preco_unitario": 899.90,
"categoria": "Periféricos"
},
{
"produto_id": 4,
"nome": "Processador Intel Core i7 12700K",
"quantidade": 1,
"preco_unitario": 1799.00,
"categoria": "Hardware"
},
{
"produto_id": 5,
"nome": "Placa Mãe ASUS Prime Z690-P",
"quantidade": 1,
"preco_unitario": 1299.00,
"categoria": "Hardware"
},
{
"produto_id": 6,
"nome": "Mouse Gamer RGB",
"quantidade": 1,
"preco_unitario": 199.00,
"categoria": "Periféricos"
},
{
"produto_id": 7,
"nome": "Teclado Mecânico RGB",
"quantidade": 1,
"preco_unitario": 349.00,
"categoria": "Periféricos"
}
],
"pagamento": {
"metodo": "cartao_credito",
"parcelas": 6,
"valor_total": 5539.70,
"moeda": "BRL",
"status": "pago"
},
"entrega": {
"transportadora": "Correios",
"codigo_rastreamento": "BR1234567890",
"data_prevista": "2025-11-03",
"frete": 39.90,
"status": "em_transporte"
}
}
Além desses, também podemos considerar o cenário event sourcing. Então, nesse modelo todos os eventos são armazenados num local para posterior consulta, auditoria ou mesmo execução de computações. Um exemplo possível seria o controle de movimentações financeiras de uma conta bancária. Cada movimentação gera um evento que faz uma entrada num banco de dados. Para saber o saldo de uma conta seria necessário uma totalização das entradas.
Alto volume e escala em tempo real
Entendemos, então que quando falamos de grandes escalas o RabbitMQ pode não ser suficiente. Mas, além disso, quando falamos de stream de dados, ele pode não ser a solução mais adequada. Então, é nesse contexto que o Kafka reina, tendo uma capacidade de escala maior e estruturas específicas para lidar com volumes muito grandes.
O Kafka é um message broker criado pelo Linkedin mas hoje é mantido pela Apache Foundation. Ele tem uma estrutura distribuída, lida com eventos em tempo real, lida bem tanto com event notifications quanto streams, possui uma estratégia de particionamento, armazenamento dos eventos, entre outros.
Compreendendo o Apache Kafka
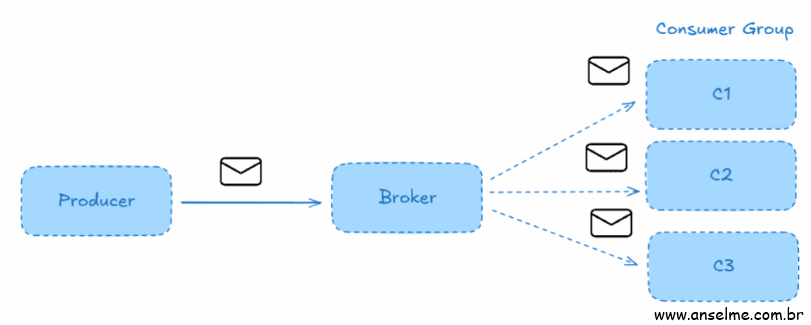
Os producers são as aplicações que emitem eventos. Elas tem capacidade de enviar num formato binário específico, aceito pelo Kafka. Diversos brokers podem enviar mensagens para um mesmo broker, sem problemas. Entretanto os producers podem agrupar as mensagens enviadas em lote através de chaves, que veremos melhor mais a seguir.
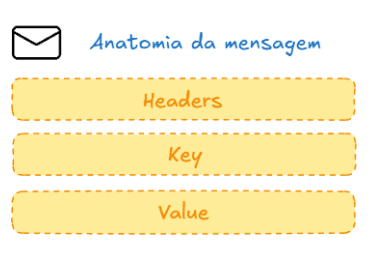
Vendo a anatomia da mensagem kafka notamos que há 3 estruturas: os headers que indicam estruturas de controle num modelo de chave-valor; mensagem; as keys que indicam que mensagens correlacionadas serão armazenadas numa mesma partição; já o value carrega a mensagem em si.
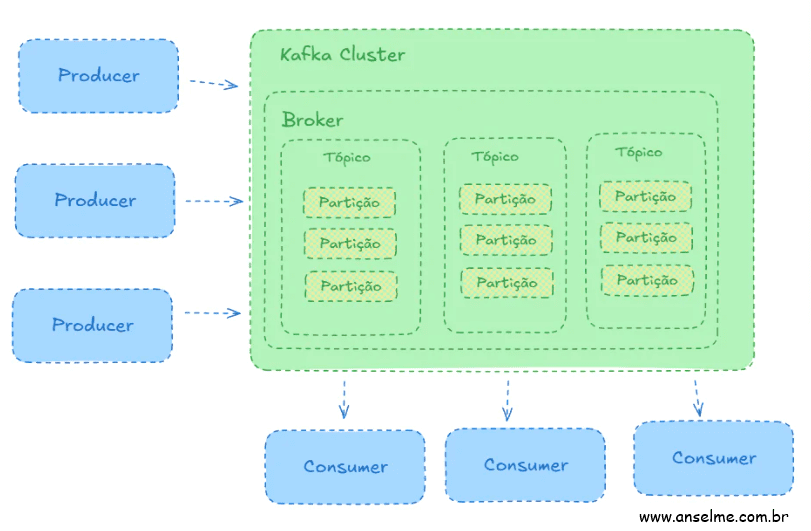
Os vários producers podem gerar mensagens indicando chaves de partição que segregam logicamente as mensagens e propicia uma escalabilidade para o kafka e para os consumers. O Kafka possui um Service Discovery interno capaz de dinamicamente (se assim configurado) aumentar a quantidade de serviços que o sustentam. Versões mais antigas utilizam o Apache Zookeeper mas as novas utilizam um sistemas próprio e específico, o KRaft.
No lado do consumo há o conceito do consumer group, que agrega diferentes consumidores de forma a dar escalabilidade ao mesmo tempo garantindo que cada partição de um tópico seja lida por apenas uma única instância de consumidor.
Casos de uso do Apache Kafka
Agora vamos a alguns casos de uso que fazem sentido cogitar uma solução como o Kafka.
1. Integração de Sistemas (Event Streaming)
Nesse caso o Kafka atua como o barramento de eventos central que conecta sistemas heterogêneos: Em vez de fazer com que os sistemas se comuniquem diretamente (o que os torna dependentes uns dos outros), o sistema A simplesmente publica um evento no Kafka. O sistema B, C e D podem consumir esse evento de forma assíncrona, desacoplando o fluxo de dados e facilitando a adição ou remoção de novos sistemas.
2. Comunicação entre Microserviços e sistemas distintos em tempo real.
A base da Arquitetura Orientada a Eventos (EDA): Microserviços se comunicam por meio de eventos publicados em tópicos do Kafka, em vez de chamadas síncronas de API (ex: HTTP). Isso torna a arquitetura mais resiliente, pois um serviço pode falhar sem derrubar a cadeia de processamento, e mais escalável, permitindo o processamento paralelo de eventos.
3. Agregação de Logs e Observabilidade
Centralização de todos os logs, métricas e telemetrias de diversas fontes: o Kafka coleta dados de log de milhares de servidores, aplicações e dispositivos, atuando como um buffer persistente. Então, isso permite que times de operações e segurança tenham um ponto único de acesso para ferramentas de monitoramento, garantindo que nenhum dado seja perdido mesmo durante picos de tráfego.
4. Processamento de Dados em Tempo Real (Streaming Analytics)
Análise e transformação contínua de dados em movimento: Usando bibliotecas como Kafka Streams ou ksqlDB, o Kafka permite que as aplicações leiam dados de um tópico, apliquem transformações, junções ou agregações (como calcular a média das transações no último minuto) e publiquem os resultados em um novo tópico, tudo com baixa latência.
5. IoT e Sensores
Coleta, ingestão e processamento de dados massivos de dispositivos conectados: Dispositivos IoT (carros, máquinas industriais, wearables) geram um volume de dados extremamente alto e contínuo (time-series data). Assim, o Kafka é ideal para receber esse volume massivo de forma eficiente, persistindo-o e distribuindo-o para aplicações que precisam processar os dados imediatamente, como detecção de anomalias.
6. ETL em Tempo Real (Data Ingestion)
Modernização de pipelines de extração, transformação e carga (ETL) de batch para stream: O Kafka Connect é frequentemente usado para extrair dados em tempo real de bancos de dados ou APIs (a etapa E de Extração) e enviá-los para um tópico. De lá, as transformações (T) são feitas por processadores de stream, e a carga (L) é feita em tempo real para data lakes (como S3) ou data warehouses (como Snowflake).
7. Event Sourcing e CQRS
Padrões de arquitetura baseados em registrar todas as mudanças de estado como uma sequência de eventos: O Kafka atua como o log imutável de eventos (o “diário” do sistema). Assim, em vez de armazenar o estado atual em um banco de dados, o sistema armazena todos os eventos que levaram a esse estado. Então, se o estado for perdido, ele pode ser reconstruído a qualquer momento lendo todos os eventos do Kafka (Event Sourcing).
8. Sincronização de Bancos de Dados
Captura de Mudança de Dados (Change Data Capture) para replicar dados entre sistemas: Ferramentas como o Debezium (que utiliza o Kafka Connect) monitoram o log de transações de um banco de dados (ex: MySQL, PostgreSQL). Cada INSERT, UPDATE ou DELETE é capturado como um evento e enviado a um tópico do Kafka. Então, isso permite sincronizar cópias de bancos de dados, alimentar caches ou acionar microsserviços imediatamente após uma alteração.
9. Arquiteturas Multi-Cloud
Conectar e compartilhar dados entre ambientes que utilizam diferentes provedores de nuvem (AWS, Azure, GCP): o Kafka (ou clusters Kafka em diferentes nuvens) serve como um hub neutro. Assim, usando recursos de replicação (como MirrorMaker), você pode garantir que um evento produzido no Azure seja consumido por uma aplicação na AWS, resolvendo a complexidade de integração entre fronteiras de nuvem.
10. Data Mesh
Um modelo organizacional e arquitetural que trata os dados como um produto: No conceito de Data Mesh, os tópicos do Kafka são o principal mecanismo para entregar os Produtos de Dados. Desse modo, em vez de uma equipe centralizada de ETL mover todos os dados, equipes de domínio (ex: Vendas, Estoque) produzem seus dados em tópicos Kafka, que se tornam produtos prontos para serem consumidos por qualquer outro domínio que precise deles.
Conclusão de Casos de uso do Apache Kafka
Casos de uso do Apache Kafka. Então, o Apache Kafka é a plataforma para arquiteturas orientadas a eventos e dados em tempo real. Assim, sua estrutura distribuída, seu protocolo otimizado, e o modelo de particionamento superam as limitações dos message brokers tradicionais em ambientes de grande porte. Vimos que essa robustez o torna essencial para uma vasta gama de aplicações. Seja para desacoplar microserviços, centralizar logs, executar streaming analytics, ou suportar padrões avançados. Então, ele continuamente confirma sua relevância como componente essencial na engenharia de sistemas modernos.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
